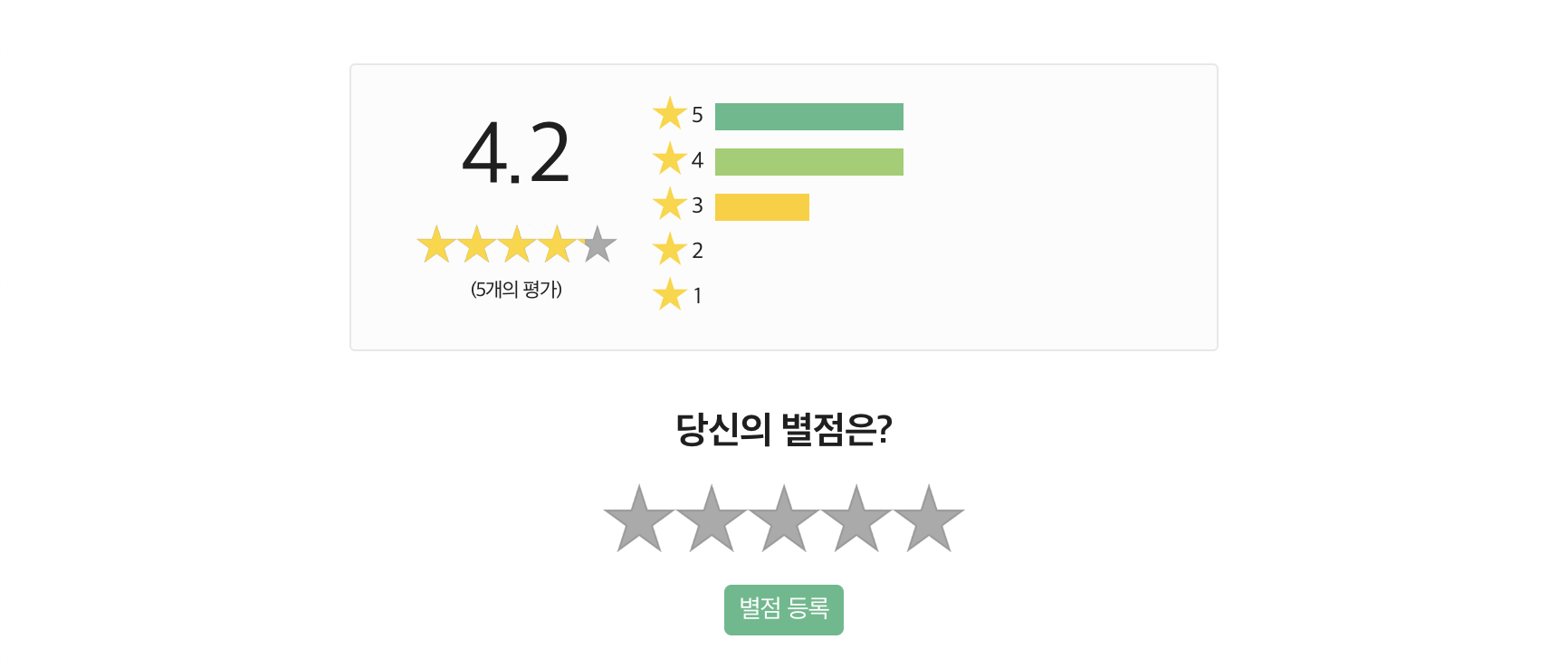
배달 음식 가게 리뷰를 보다 보면 별점 5점 평가를 자주 접하곤 한다. 그런데 별점 평가가 평균이 돼 있다. 단지 “만족합니까?” 한 가지 질문을 하고는 무엇에 만족해서 높은 점수는 줬는지는 모를 평가로 다른 사람의 응답을 평균을 계산하는 식이다. 그도 그럴 것이 무엇이 만족스러웠는지도 묻지 않는다.

이러한 방식을 Likert scaling이라 부른다. 정확히는 별점 평가가 결코 Likert scaling이라 할 수 없음에도.
5점 평가의 정확성?
별점 평가가 정확할까? 아니다. 부정확하다. 5점 평가는 동양에서 부정확하게 동작한다. 그렇다면 7점 평가로 늘리면 더 정확한가? 아니다. 역시 부정확하다. 동양권에서 실험한 바로는 그렇다. 선택지를 늘리면 정확할 거 같지만 선택지를 늘리면 늘릴 수록 더 부정확해졌다. 가장 정확한 응답이 이루어졌던 건 4점 척도 조건이었다.
그래서 각종 만족도 조사에서 1점부터 5점을 매기라고 하고 있지만, 이상하게도 정확한 측정이 불가능하다. 맥락에 따라 “보통이다” 혹은 “매우 만족”을 선택할 테니까. “보통이다”를 선택하는 응답 경향성을 중심 응답 경향성(MRS: Middle Response Style), “매우 만족”을 선택하는 응답 경향성을 “극단 응답 경향성”(ERS: Extreme Response Style)이라 부른다.

특히 여러 연구에서 보고된 바를 정리한 결과를 따르면, 동아시아권 국가에서 실제 인식보다 더 강하게 응답하는 경향(극단 응답 경향성)이 다른 국가에 비해 강했다. 이러한 결과가 “매우 만족”평가만을 원하는 상황이 되었고, 평가가 보상 문제와 엮이면서 더 상황을 악화하는 것 아닐까.
근본 질문: 근데 별점이 평균 낼 수 있는 거였나?
그런데 근본 질문을 놓치면 안 된다. Likert scaling으로 얻은 답변을 평균을 낼 수 있었나? Likert scaling은 원래 서열 척도(ordinal scale)로 질문을 한다. 그래서 원래는 서열 척도로 받은 응답을 수치로 변환하는 계산 방식이 있다. 그런데 어쩌다 보니 후대 연구자가 계산이 편하도록 1부터 5라는 숫자를 부여하게 되었고 지금까지 문제 의식 없이 사용해 왔다. 즉, 별점은 평균 내선 안 된다. 이게 원칙이다. 최근 연구는 5점 이하의 척도는 반드시 서열 척도로 취급하여 계산을 해야 한다 보고했다.
그리고 한 가지 더. Likert scaling 자체가 부정확한 상황이 있다. 질문에 어떤 의도가 있어 만족을 묻거나, ‘만약에’라는 말이 붙거나 두 가지 이상의 조건이 붙어서 질문이 애매모호한 경우다. 이런 상황에 빠지면 단순 합산한 평가 점수가 높다 하더라도 이를 믿을 수 없고 실제로는 중간 어딘가 평가를 한 사람의 의견이 더 중요해진다.
이러느니 차라리 좋아요 버튼이 낫다!
사람은 생각보다 대충 판단하는 존재다. 4점 척도 조건을 주었을 때 5점과 7점보다 더 정확했음을 상기해 본다면, 선택지를 좀 줄여 줄 필요가 있다. 그런데 3점을 준다면 중심 응답 경향성이 나타날 가능성이 있다. 애매모호하면 ‘보통’이라 하는 현상이다. 그러면 결국엔 남는 건 만족 또는 불만족이다. 정말 Likert scaling처럼 점수를 계산하고 싶다면 차라리 좋아요 버튼 하나면 된다. 업데이트 후 종료에서 누적 기제(cumulative response process)와 전개 기제(ideal response process)를 설명할 수는 없지만 실험 결과는 분명하다. 예 또는 아니오로 구성된 자료가 훨씬 분석하기에 좋았다.
나쁜 평가에 더 귀 기울이는 사회가 되려면 피드백 기술이 필요하다.
좋은 평가에는 상세한 이유가 없으나, 나쁜 평가에는 상세한 이유가 있다. 무엇인가 더 잘 해 낼 수 있을 거 같은데 기대보다 결과가 안 좋은 경우 충분히 그럴 수 있다. 그런데 나쁜 걸 기술 없이 말하면 상대는 듣지 않는다. 나쁜 걸 악평을 쏟아내기 보다는 잘 할 수 있을만한 걸 어떻게 하면 될지 강점을 중심으로 조곤조곤 말해 보는 게 어떨까.
평가는 성장과 도약을 위해 존재해야 하지, 누군가를 망하게 해서는 안 된다.



